
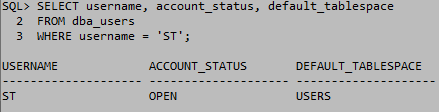
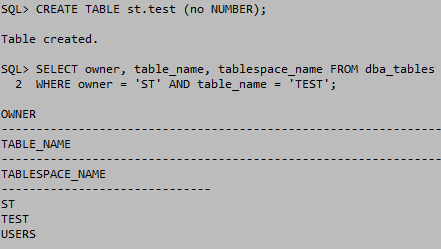
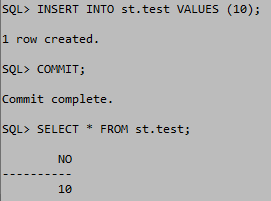
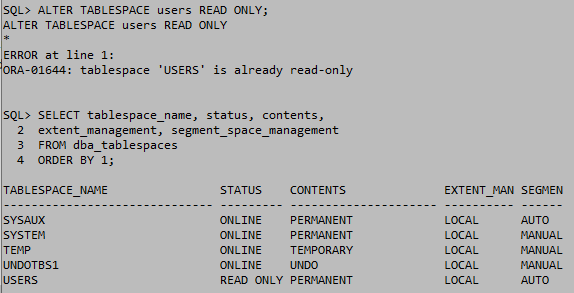
읽기전용 테이블 스페이스
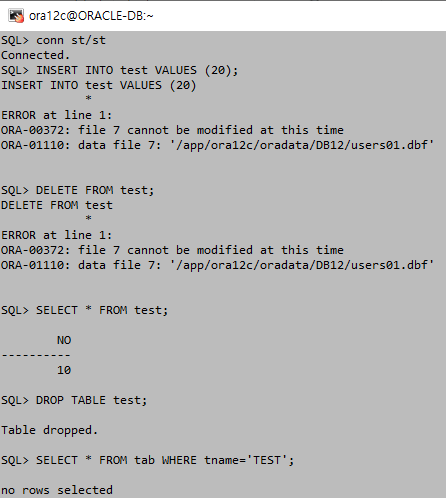
읽기전용 테이블 스페이스는 테이블 스페이스 내의 데이터파일을 전부 READ ONLY상태로 바꿔준다. 따라서 수정이 불가능 하지만 DROP은 가능하다. 데이터파일의 내용을 수정하는 것과 데이터파일을 삭제 하는 것은 다르기 때문이라고 생각한다. 그리고 DROP이 가능하다면 읽기전용을 사용할 필요가 있을까에 대한 답은 데이터에 대한 조회를 해야 그 데이터에 의미가 있기 때문이라고 생각한다. 하지만 읽기전용을 하지 않는다면 수정이 가능해지기 때문에 읽기전용의 의의가 여기 있다고 생각한다.
open상태에서 테이블 스페이스 이동
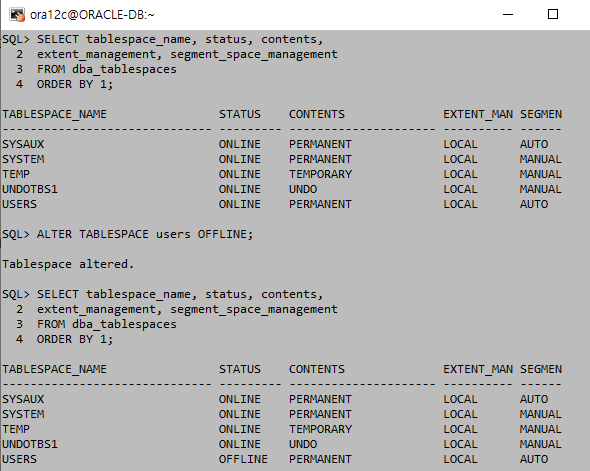
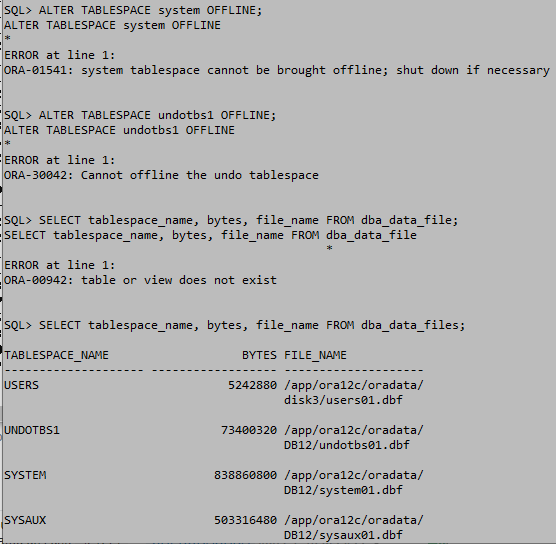
이 상태에서는 테이블스페이스를 offline으로 변경하여 작업을 수행한다. 당연히 사용자가 임의로 사용이 불가능한 SYSTEM이라는 이름의 테이블 스페이스와 실행취소 세그먼트가 있는 테이블 스페이스, 기본임시 테이블 스페이스는 offline 작업을 할 수 없다.
offline으로 설정하는 것은 'ALTER TABLESPACE 테이블스페이스명 OFFLINE;'을 사용한다. 이렇게 되면 해당 테이블 스페이스는 mount의 상태가 되어 테이블스페이스에서의 작업이 가능해 진다. online으로 설정하면 'ALTER TABLESPACE 테이블스페이스명 ONLINE;'을 사용하면 되며, online으로 상태를 변경하기 전에 변경사항을 제대로 수행해야 한다.
close상태에서 테이블 스페이스 이동
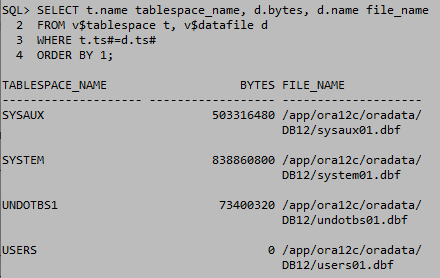
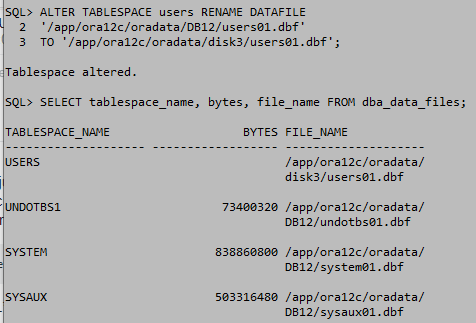
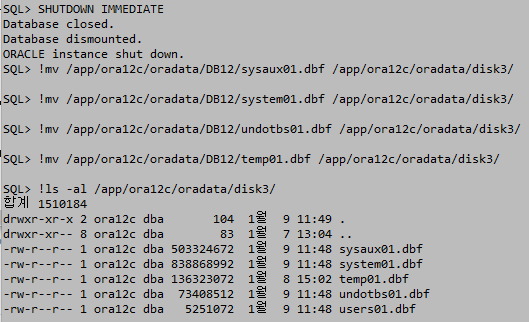
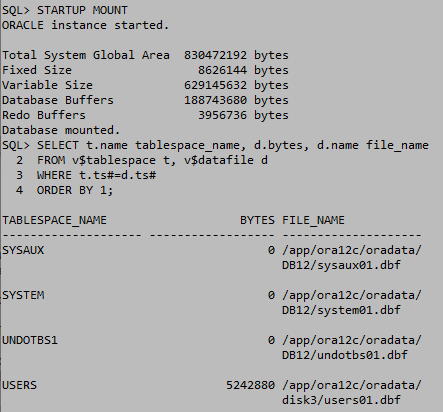
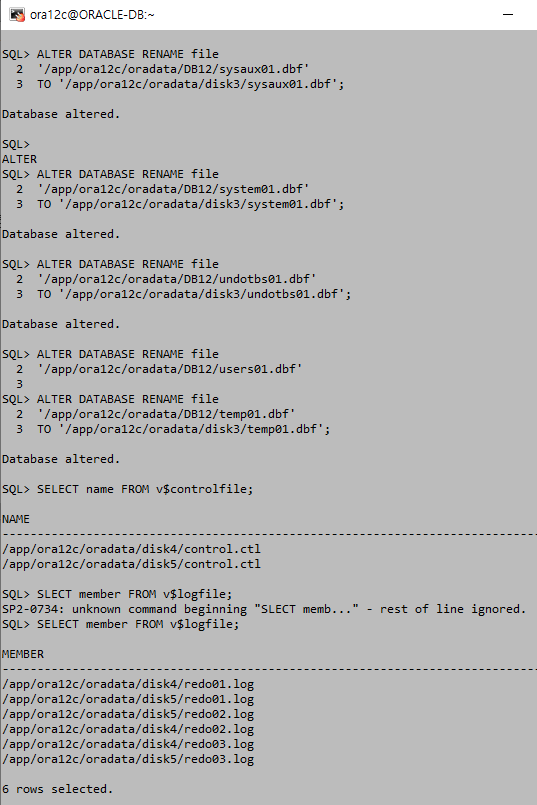
online일때는 마운트를 shutdown 상태로 실행한다. shutdown상태에서는 거의 모든 데이터 테이블을 삭제할수있다. DB를 shutdown하고 데이터파일을 이동하고 마운트 상태로 올려준다. ALTER DATABASE명령으로 데이터 파일을 등록하고 DB를 open한다.





임시 테이블스페이스
임시 테이블 스페이스는 정렬 작업에 사용한다. PGA안에 SORT AREA SIZE만큼을 할당받아 사용한다. DB는 데이터의 양이 많을때 그리고 생설될 데이터도 많을 경우에 사용한다. 정렬은 빠르게 할 방법이 없다.
select * from emp는 따로 정렬없이 출력이 가능하므로 바로 출력된다. 따라서 데이터가 출력되는 순서에는 아무런 의미가 없다. 하지만 조건을 넣게 되면 정렬을 해야 하기 때문에 시간이 지나 출력이 된다. 따라서 인덱스를 사용한다. 인덱스로 이미 정렬된 데이터를 행마다 출력하는 방식을 사용하므로 처리 속도가 굉장히 빠르다.
이런 방식을 sort하고 merge한다고 한다. 큰 데이터를 databuffer cache가 한번에 데이터를 처리할 수 없기 때문에 일정한 크기로 잘라서 그룹을 만들고 sort한다. 그룹을 임시 테이블스페이스에 저장하고 저장된 그룹에서 앞의 크기를 비교해 가면서 작은 값부터 가져온다. 가져오면서 출력하는 것을 merge라고 한다.
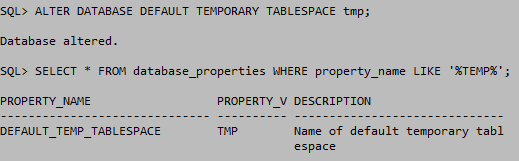
기본 임시테이블 스페이스는 offline으로 변경 및 제어를 할 수 없다. 임시 테이블 스페이스를 지정하지 않게 되면 기본 임시테이블 스페이스를 사용한다. 기본 임시 테이블은 오라클이 설치될때 자동적으로 생성되는 테이블 스페이스 이다. 데이터베이스의 기본 임시 테이블 스페이스를 찾기 위해서는DATABASE_PROPERTIES를 참조한다.
기본 임시 테이블스페이스는 다른 임시테이블스페이스를 기본값으로 설정하기 전까지 삭제가 불가능하며 오프라인으로 설정이 불가능하다. 당연하지만 임시적으로 저장하는 테이블스페이스기 때문에 영구 테이블 스페이스로 변경이 불가능 하다.





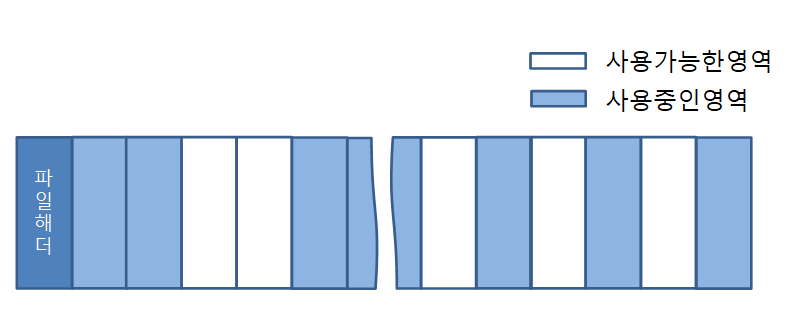
저장영역 및 관계 구조 사진
DB영역 안에서 Block size는 전부 동일하다. 테이블 스페이스 1개당 temp 세그먼트는 1개씩 있다. RBS는 언두테이블 스페이스는 1개에 여러 언두 세그먼트를 가질 수 있다. 시스템이라는 이름의 테이블스페이스에 시스템테이블스페이스 전용의 언두세그먼트가 있다. 시스템 세그먼트는 자체적으로 템프 세그먼트도 가질수있다. 데이터 딕셔너리에 대한 데이터세그먼트와 인덱스 세그먼트는 시스템 테이블 스페이스에 있다.
세그먼트의 유형은 11가지가 있다.
테이블에 대한 유형으로는 일반적인 테이블형태의 세그먼트인 regular table 세그먼트가 있다.
테이블 분할 세그먼트는 테이블이 너무 커서 검색시간이 오래 걸릴때 사용한다. 물리적으로 크기를 여러개로 분할하여 저장하는 것이다. 테이블 일부를 이동 또는 하드디스크 분리가 가능하다.
클러스터 세그먼트는 실행계획을 세우는 optimier가 실행계획을 무시하고 선호하는 클러스터나 인덱스를 사용하는 일이 생기기도 한다. 하지만 클러스터 방식은 굉장히 처리속도가 빠르고 다른 테이블에 영향이 없을 경우 사용한다.
인덱스 방식은 순환하지 않는 일방향성 트리구조이다. 가장 상위노드를 루트노드라고 하며 가변적이다. 마지막 노드는 터미널노드, 리프노드라고 하며, 중간노드를 브런치 노드라고 한다. 루트 노드에서 리프노드까지의 거리는 모두 같다. 일반 트리는 하향성으로 커지며 모든 노드에 데이터가 분산 저장되어있다. DB 트리는 상향성이며 데이터는 리프노드에만 있다.
인덱스 구성 테이블은 RDB원칙에 어긋나기 때문에 10버전 부터는 사용하지 않는다. RDB는 application으로 부터 독립적이기 때문에 사용하는데 인덱스 구성 테이블은 특정 걸럼에 대해 인덱스로 구성되기 때문이다.
인덱스 분할 영역은 인덱스를 분할하여 여러 테이블 스페이스에 분산하는 것이다. 실행 취소 세그먼트는 데이터베이스를 변경 중인 트랜잭션이 저장되는 세그먼트이다. 임시 세그먼트는 정렬에 사용하는 sort set이 저장되는 세그먼트 이다. LOB세그먼트는 CLOB과 BLOB이 있는데 크기가 큰 파일을 저장할때 사용한다. 하지만 4GB까지 저장되며 검색은 되지 않는다. 실제 예를들어 인터넷에서 파일이동은 하드웨어에 바로 하고 DB에서는 경로등 정보만 저장하는 역할을 한다. 부트스트랩세그먼트는 startup시 사용하는 세그먼트이다.
저장영역 절 우선순위는 dictionary management에 사용하기 때문에 패스한다.
확장영역 할당 및 할당해제
확장영역은 테이블스페이스 내에서 세그먼트가 사용하는 공간조각으로 세그먼트가 생성되거나 확장될때는 자동적으로 부여되고 변경될때는 강제로 공간을 부여한다.
할당해제는 삭제하는 경우 할당해제되고, ALTER로 할당을 해제하는것은 H/M밖의 extent를 없애는 것인데 H/M밖의 extent는 존재 하지 않기때문에 변동사항이 없어야 정상이다.
truncate하는 경우에는 테이블을 drop 후 다시 생성되는 것과 같다.
사용된 확장영역 및 사용 가능한 확장 영역
여기서 dictionary management와 locally management의 차이가 나타난다.
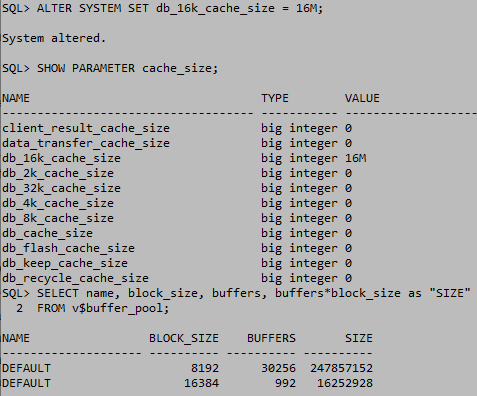
만약 block크기가 1M라면 2M파일은 저장할수없다. 하지만 locally는 하나의 block으로 생각하기 때문에 저장이 가능하다. 블록은 테이블 스페이스 생성시 설정하며 DB_BLOCK_SIZE는 Standard Block Size라고도 하며 기본 블록 크기로 수정이 불가능하다. 테이블 생성시 생성하는 블록은 크기를 정할수있는데 2KB~32KB사이의 2^n으로 크기를 설정한다. 이것을 비 표준 블록이라고 한다. 비표준 블록크기의 테이블 스페이스는 많은양의 데이터를 통합 운영하는 다중 DB에서 사용한다.
어떤DB에서는 표준인 8K이하의 데이터를 저장해서 많은 접속이 이루어지는DB가 있고 어떤 DB는 접속 횟수는 적지만 표준인 8K를 넘는 데이터를 저장해서 사용하는 DB가 있다. 그런 DB를 통합해서 한 서버에서 처리가 이루어질때에는 해당 DB에 적절한 블록 크기를 주는것이 필요하다. 비 표준 블록 크기를 구성하는 캐시의 최소크기는 1그래뉼이다.
데이터베이스의 블록은 헤더와 사용 가능한 영역, 데이터로 이루어져 있으며 segment_space_management에서 확인이 가능하다.
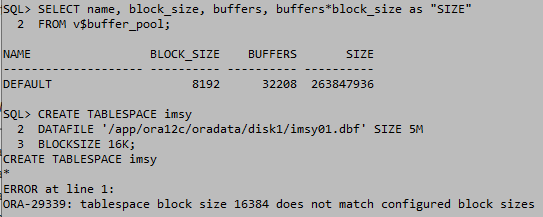
테이블 스페이스를 생성하기 전에 반드시 데이터베이스 버퍼 캐시를 생성해야 한다.
DB메모리의 특징은 동적이며 관점에 따라 소속이 달라져 보는 섹션에 따라 크기가 달라질수있다..
파라미터값에서 볼수있는 db_cache_size는 db_buffer_cache의 크기를 나타내는데 value가 0인 이유는 자동으로 할당하기 때문에 설정하지 않겠다는 의미이다.
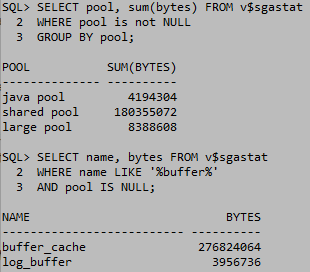
SHOW PARAMETER sga_ 에서 sga_max_size의 용량은 v$sgastat에서 나오는 java pool, shared pool, large pool, buffer_cache, log_buffer의 합보다 크다. 왜냐하면 v$sgastat의 합은 최소한으로 사용하기위해 미리 확보한 크기고, sga_max_size가 용량의 한계이다.





'교육 > Oracle' 카테고리의 다른 글
| Day 40 (DB) (0) | 2020.01.14 |
|---|---|
| Day 39 (DB) (0) | 2020.01.13 |
| Day 36(Oracle) (0) | 2020.01.08 |
| Day 35 (Oracle DB) (0) | 2020.01.07 |
| Day 34 (Oracle DB) (0) | 2020.01.06 |



